// 调用toArray()方法获取当前的二叉堆 public Iterator<E> iterator() { returnnewItr(toArray()); }
/** * Snapshot iterator that works off copy of underlying q array. */ finalclassItrimplementsIterator<E> { final Object[] array; // Array of all elements int cursor; // index of next element to return int lastRet; // index of last element, or -1 if no such
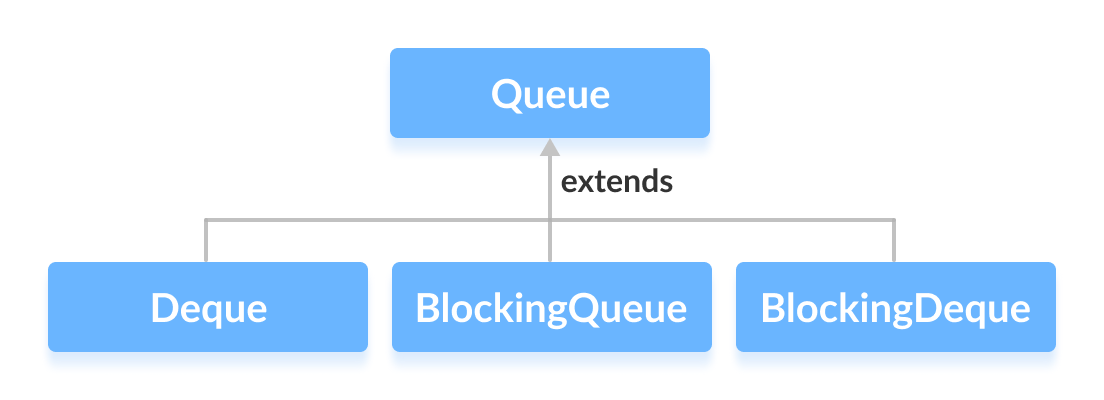
SynchronousQueue的内部实现了两个类,一个是TransferStack类,使用LIFO顺序存储元素,这个类用于非公平模式;还有一个类是TransferQueue,使用FIFI顺序存储元素,这个类用于公平模式。这两个类继承自”Nonblocking Concurrent Objects with Condition Synchronization”算法,此算法是由W. N. Scherer III 和 M. L. Scott提出的,关于此算法的理论内容在这个网站中:http://www.cs.rochester.edu/u/scott/synchronization/pseudocode/duals.html。两个类的性能差不多,FIFO通常用于在竞争下支持更高的吞吐量,而LIFO在一般的应用中保证更高的线程局部性。
/* Modes for SNodes, ORed together in node fields */ /** 表示一个未满足的消费者 */ staticfinalintREQUEST=0; /** 表示一个未满足的生产者 */ staticfinalintDATA=1; /** Node is fulfilling another unfulfilled DATA or REQUEST */ staticfinalintFULFILLING=2;
staticbooleanisFulfilling(int m) { return (m & FULFILLING) != 0; }
/** Node class for TransferStacks. */ staticfinalclassSNode { volatile SNode next; // 栈中的下一个结点 volatile SNode match; // 匹配此结点的结点 volatile Thread waiter; // 控制 park/unpark Object item; // 数据 int mode;
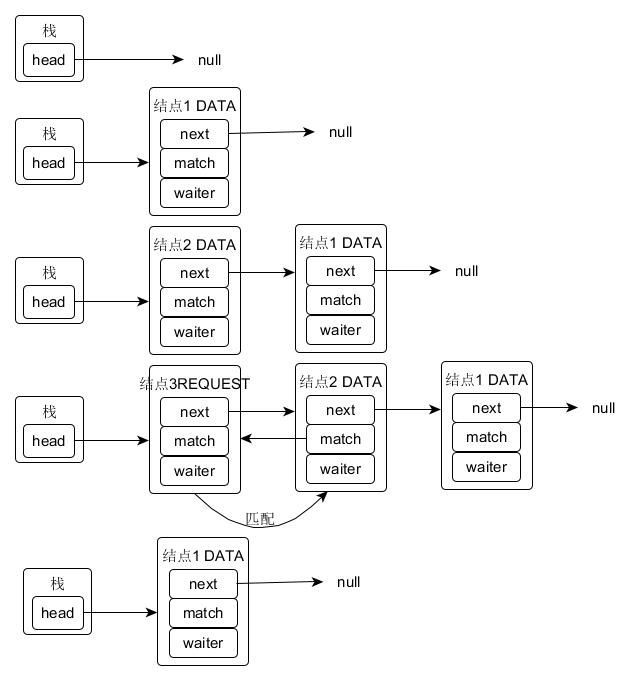
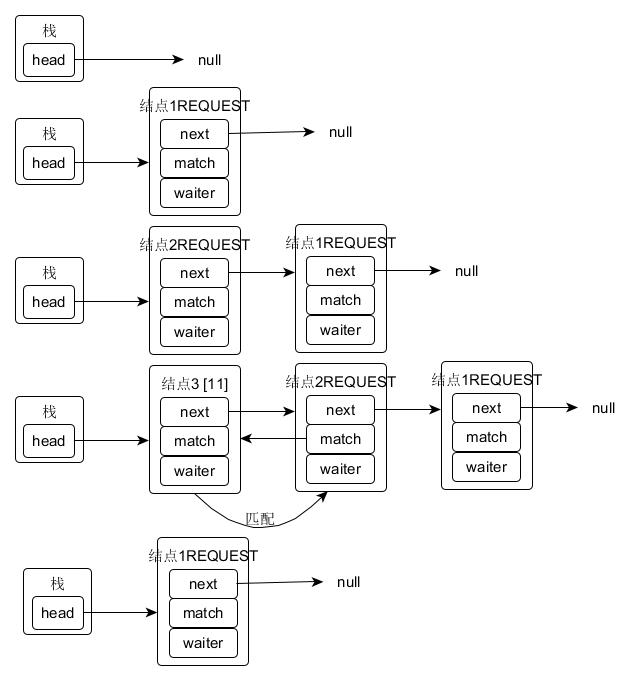
SNodes=null; // constructed/reused as needed // 传入参数为null代表请求获取一个元素,否则表示插入元素 intmode= (e == null) ? REQUEST : DATA;
for (;;) { SNodeh= head; // 如果头节点为空或者和当前模式相同 if (h == null || h.mode == mode) { // empty or same-mode // 设置超时时间为 0,立刻返回 if (timed && nanos <= 0L) { // can't wait if (h != null && h.isCancelled()) casHead(h, h.next); // pop cancelled node else returnnull; // 构造一个结点并且设为头节点 } elseif (casHead(h, s = snode(s, e, h, mode))) { // 等待满足 SNodem= awaitFulfill(s, timed, nanos); if (m == s) { // wait was cancelled clean(s); returnnull; } if ((h = head) != null && h.next == s) casHead(h, s.next); // help s's fulfiller return (E) ((mode == REQUEST) ? m.item : s.item); } // 检查头节点是否为FULFILLIING } elseif (!isFulfilling(h.mode)) { // try to fulfill if (h.isCancelled()) // already cancelled casHead(h, h.next); // pop and retry // 更新头节点为自己 elseif (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { // 循环直到匹配成功 for (;;) { // loop until matched or waiters disappear SNodem= s.next; // m is s's match if (m == null) { // all waiters are gone casHead(s, null); // pop fulfill node s = null; // use new node next time break; // restart main loop } SNodemn= m.next; if (m.tryMatch(s)) { casHead(s, mn); // pop both s and m return (E) ((mode == REQUEST) ? m.item : s.item); } else// lost match s.casNext(m, mn); // help unlink } } // 帮助满足的结点匹配 } else { // help a fulfiller SNodem= h.next; // m is h's match if (m == null) // waiter is gone casHead(h, null); // pop fulfilling node else { SNodemn= m.next; if (m.tryMatch(h)) // help match casHead(h, mn); // pop both h and m else// lost match h.casNext(m, mn); // help unlink } } } }
/* * At worst we may need to traverse entire stack to unlink * s. If there are multiple concurrent calls to clean, we * might not see s if another thread has already removed * it. But we can stop when we see any node known to * follow s. We use s.next unless it too is cancelled, in * which case we try the node one past. We don't check any * further because we don't want to doubly traverse just to * find sentinel. */
SNodepast= s.next; if (past != null && past.isCancelled()) past = past.next;
// 删除头部被取消的节点 SNode p; while ((p = head) != null && p != past && p.isCancelled()) casHead(p, p.next);
// 移除中间的节点 while (p != null && p != past) { SNoden= p.next; if (n != null && n.isCancelled()) p.casNext(n, n.next); else p = n; } }
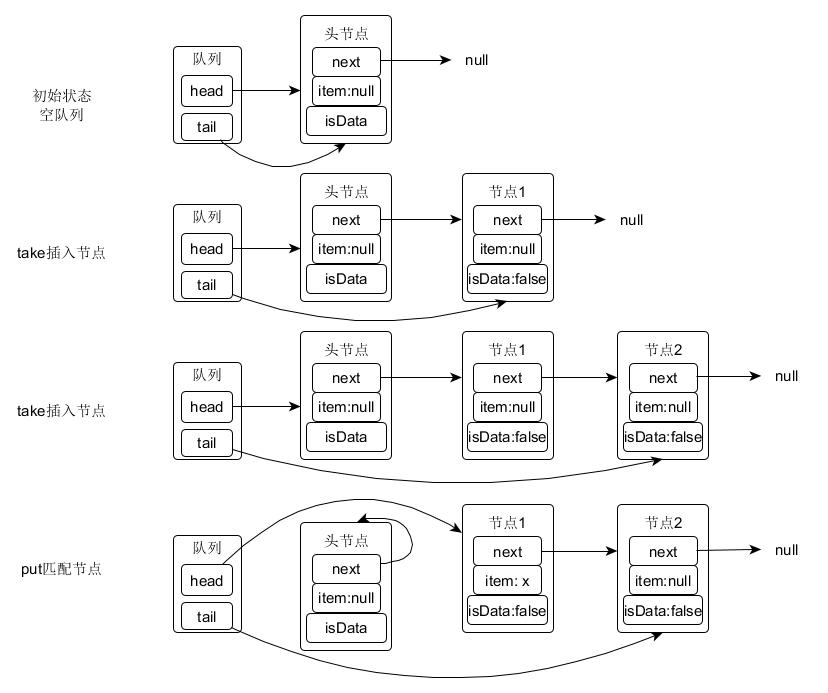
TransferQueue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
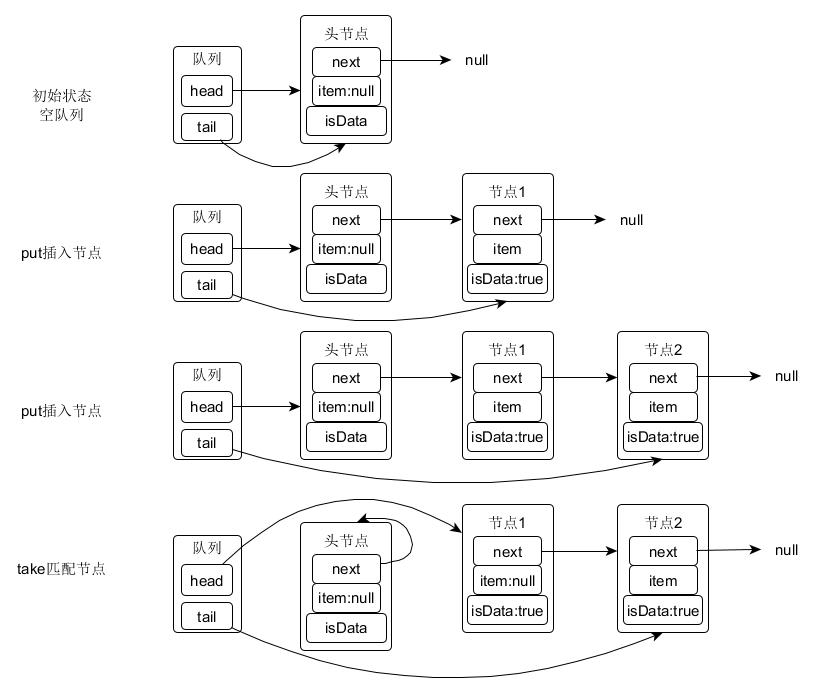
staticfinalclassTransferQueue<E> extendsTransferer<E> { /* * This extends Scherer-Scott dual queue algorithm, differing, * among other ways, by using modes within nodes rather than * marked pointers. The algorithm is a little simpler than * that for stacks because fulfillers do not need explicit * nodes, and matching is done by CAS'ing QNode.item field * from non-null to null (for put) or vice versa (for take). */
/** Node class for TransferQueue. */ staticfinalclassQNode { volatile QNode next; // next node in queue volatile Object item; // CAS'ed to or from null volatile Thread waiter; // to control park/unpark finalboolean isData;
E transfer(E e, boolean timed, long nanos) { /* Basic algorithm is to loop trying to take either of * two actions: * * 1. If queue apparently empty or holding same-mode nodes, * try to add node to queue of waiters, wait to be * fulfilled (or cancelled) and return matching item. * * 2. If queue apparently contains waiting items, and this * call is of complementary mode, try to fulfill by CAS'ing * item field of waiting node and dequeuing it, and then * returning matching item. * * In each case, along the way, check for and try to help * advance head and tail on behalf of other stalled/slow * threads. * * The loop starts off with a null check guarding against * seeing uninitialized head or tail values. This never * happens in current SynchronousQueue, but could if * callers held non-volatile/final ref to the * transferer. The check is here anyway because it places * null checks at top of loop, which is usually faster * than having them implicitly interspersed. */
QNodes=null; // constructed/reused as needed booleanisData= (e != null);
for (;;) { QNodet= tail; QNodeh= head; if (t == null || h == null) // saw uninitialized value continue; // spin
// 如果队列为空或者模式与头节点相同 if (h == t || t.isData == isData) { // empty or same-mode QNodetn= t.next; // 如果有其他线程修改了tail,进入下一循环重读 if (t != tail) // inconsistent read continue; // 如果有其他线程修改了tail,尝试cas更新尾节点,进入下一循环重读 if (tn != null) { // lagging tail advanceTail(t, tn); continue; } // 超时返回 if (timed && nanos <= 0L) // can't wait returnnull; // 构建一个新节点 if (s == null) s = newQNode(e, isData); // 尝试CAS设置尾节点的next字段指向自己 // 如果失败,重试 if (!t.casNext(null, s)) // failed to link in continue; // cas设置当前节点为尾节点 advanceTail(t, s); // swing tail and wait // 等待匹配的节点 Objectx= awaitFulfill(s, e, timed, nanos); // 如果被取消,删除自己,返回null if (x == s) { // wait was cancelled clean(t, s); returnnull; }
// 如果此节点没有被模式匹配的线程出队 // 那么自己进行出队操作 if (!s.isOffList()) { // not already unlinked advanceHead(t, s); // unlink if head if (x != null) // and forget fields s.item = s; s.waiter = null; } return (x != null) ? (E)x : e;
} else { // complementary-mode QNodem= h.next; // node to fulfill // 数据不一致,重读 if (t != tail || m == null || h != head) continue; // inconsistent read
Objectx= m.item; if (isData == (x != null) || // m already fulfilled m已经匹配成功了 x == m || // m cancelled m被取消了 !m.casItem(x, e)) { // lost CAS CAS竞争失败 // 上面三个条件无论哪一个满足,都证明m已经失效无用了, // 需要将其出队 advanceHead(h, m); // dequeue and retry continue; }
publicvoidput(E e)throws InterruptedException { if (e == null) thrownewNullPointerException(); if (transferer.transfer(e, false, 0) == null) { Thread.interrupted(); thrownewInterruptedException(); } }
publicbooleanoffer(E e, long timeout, TimeUnit unit) throws InterruptedException { if (e == null) thrownewNullPointerException(); if (transferer.transfer(e, true, unit.toNanos(timeout)) != null) returntrue; if (!Thread.interrupted()) returnfalse; thrownewInterruptedException(); }
publicbooleanoffer(E e) { if (e == null) thrownewNullPointerException(); return transferer.transfer(e, true, 0) != null; }
public E take()throws InterruptedException { Ee= transferer.transfer(null, false, 0); if (e != null) return e; Thread.interrupted(); thrownewInterruptedException(); }
public E poll(long timeout, TimeUnit unit)throws InterruptedException { Ee= transferer.transfer(null, true, unit.toNanos(timeout)); if (e != null || !Thread.interrupted()) return e; thrownewInterruptedException(); }
public E poll() { return transferer.transfer(null, true, 0); }