ThreadLocal源码解析02
上一节我们详细解析了set方法,现在我们来解析get方法
ThreadLocal.get 方法
ThreadLocal.get 方法相对来说简单
我们先来看下get的流程图
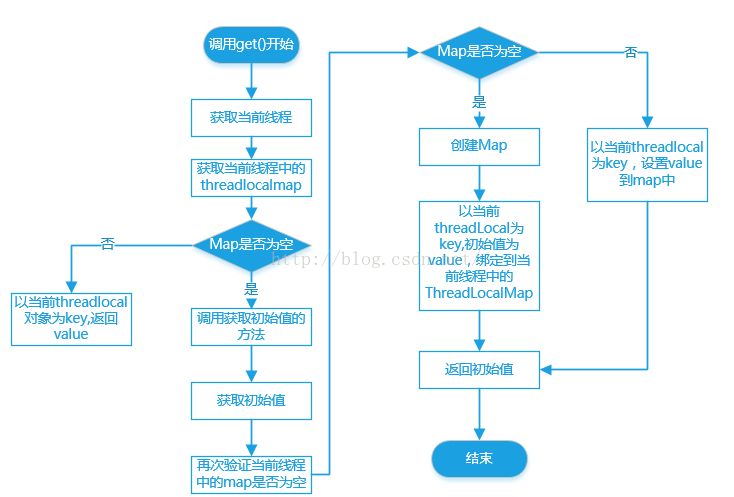
下面我们解析代码
1 | //获取ThreadLocal 中的值 |
我们发现首先从当前线程中获取ThreadLocalMap 然后从map中根据ThreadLocal获取entry,entry不为空则返回value,否则调用setInitialValue设置初始值并返回。
我们深入到 map.getEntry(this);方法
ThreadLocalMap.getEntry 方法
1 | /** |
getEntryAfterMiss
1 | /** |
到这里 get方法以及完结了。
ThreadLocal.remove 方法
1 | public void remove() { |
remove()在有上面了解后可以说极为简单了,就是找到对应的table[],调用weakrefrence的clear()清除引用,然后再调用expungeStaleEntry()进行清除。
ThreadLocal 防止hash冲突的
到这里整个threadLocal 基本介绍完成了,但是还少一块,如何处理hash冲突的
生成映射下标
1 | int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); |
这一段代码和 求模的效果类似,根据hash生成一个0-(INITIAL_CAPACITY-1)之间的数
我们发现计算冲突与threadLocalHashCode 和 INITIAL_CAPACITY有关
INITIAL_CAPACITY值的设置
例如 :
10 0001 0111 1101
00 0000 0000 1111 & (INITIAL_CAPACITY-1) 即 15
00 0000 0000 1101 13
所以这种算法只对后半段的数据敏感 如果是其他值 后面可能包含0 例如 0011 这样只有两位参与了运算,重复率就增加了,如果下面的值全是1 就更加平均了,什么时候全是1呢 就是 2的N次幂-1
例如
2^4=16=10000B
16-1=15= 01111B
所以只有当INITIAL_CAPACITY值时2的n次幂的时候才对hash的数据敏感,因为是与运算,只利用了hahs二进制的后半段。
threadLocalHashCode 值的设置
我们看下threadLocalHashCode 的声明
1 | private final int threadLocalHashCode = nextHashCode(); |
这里面有一个神奇的数字 HASH_INCREMENT
他的声明是
1 | private static final int HASH_INCREMENT = 0x61c88647; |
神奇的数字
既然ThreadLocal用map就避免不了冲突的产生
这里碰撞其实有两种类型
- 只有一个ThreadLocal实例的时候(上面推荐的做法),当向thread-local变量中设置多个值的时产生的碰撞,碰撞解决是通过开放定址法, 且是线性探测(linear-probe)
- 多个ThreadLocal实例的时候,最极端的是每个线程都new一个ThreadLocal实例,此时利用特殊的哈希码0x61c88647大大降低碰撞的几率, 同时利用开放定址法处理碰撞
注意 0x61c88647的利用主要是为了多个ThreadLocal实例的情况下用的
注意实例变量threadLocalHashCode, 每当创建ThreadLocal实例时这个值都会累加 0x61c88647,为了让哈希码能均匀的分布在2的N次方的数组里, 即 Entry[] table的大小必须是2的N次方
我们看下table的定义
1 | /** |
key.threadLocalHashCode & (len-1)这么用是什么意思? 我们上面定义了table数组的长度是16 =2^4
ThreadLocalMap 中Entry[] table的大小必须是2的N次方呀(len = 2^N),那 len-1 的二进制表示就是低位连续的N个1, 那 key.threadLocalHashCode & (len-1) 的值就是 threadLocalHashCode 的低N位, 这样就能均匀的产生均匀的分布? 我们做个实验。
1 | //神奇的数字 |
输出
1 | {0=62, 1=63, 2=62, 3=63, 4=62, 5=63, 6=62, 7=62, 8=63, 9=62, 10=63, 11=62, 12=63, 13=62, 14=63, 15=63} |
我们发现数据分布的惊人的平均,比我们写的随机数更平均。
总结
Hash冲突怎么解决
和HashMap的最大的不同在于,ThreadLocalMap结构非常简单,没有next引用,也就是说ThreadLocalMap中解决Hash冲突的方式并非链表的方式,而是采用线性探测的方式,所谓线性探测,就是根据初始key的hashcode值确定元素在table数组中的位置,如果发现这个位置上已经有其他key值的元素被占用,则利用固定的算法寻找一定步长的下个位置,依次判断,直至找到能够存放的位置。
内存泄露问题
threadlocal里面使用了一个存在弱引用的map,当释放掉threadlocal的强引用以后,map里面的value却没有被回收.而这块value永远不会被访问到了. 所以存在着内存泄露. 最好的做法是将调用threadlocal的remove方法.
因为ThreadLocal本身又清理机制,调用,get,set,remove等方法时会触发自动清理机制,清理掉key为空的主句,但是不是实时的,会有延后,在没有调用get,set,remove方法时,过期的entry时内存泄漏状态,推荐不适用了调用remove方法。
hash散列算法
在实际使用中,不同的输入可能会散列成相同的输出,这时也就产生了冲突。通过上文提到的 HASH_INCREMENT 再借助一定的算法,就可以将哈希码能均匀的分布在 2 的 N 次方的数组里,保证了散列表的离散度,从而降低了冲突几率,使用 nextHashCode & (tableSize - 1);这种方式进行下标映射性能更高,使用用HASH_INCREMENT 0x61c88647 这个神奇的数字让数据分布的更平均。