MongoDB高阶操作

准备数据
安装工具包
下载工具包
因为下载的MongoDB是不包含导入导出工具包的,到下载页面选择版本下载即可
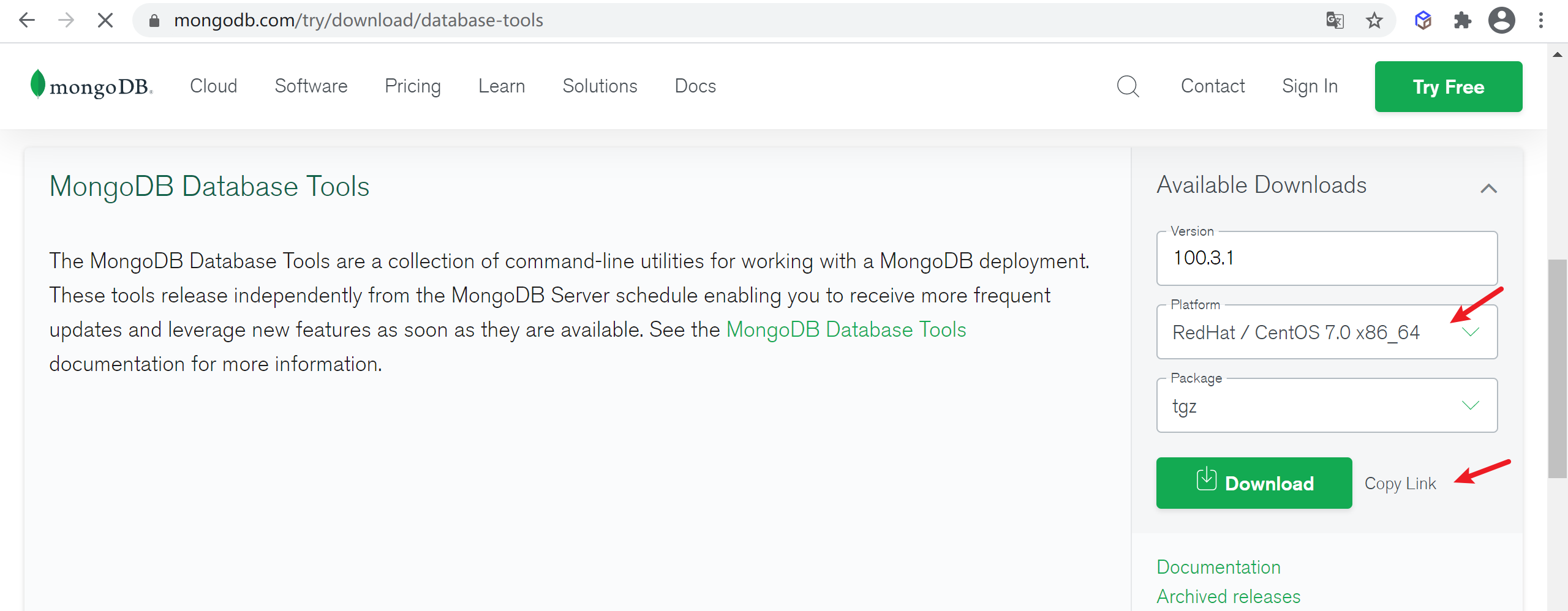
选择符合的版本下载即可
1 | wget https://fastdl.mongodb.org/tools/db/mongodb-database-tools-rhel70-x86_64-100.3.1.tgz |

安装工具包
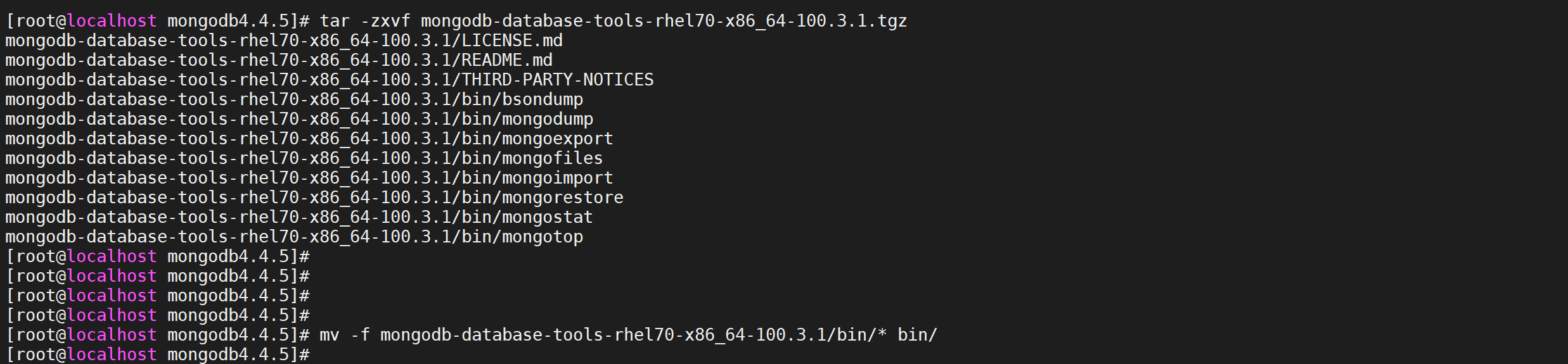
1 | 解压安装包 |
将MongoDB工具包中的文件复制到 mongodb安装目录的 bin目录
导入测试数据
下载测试数据
这里使用亚马逊官方提供的,下载地址 亚马逊测试数据
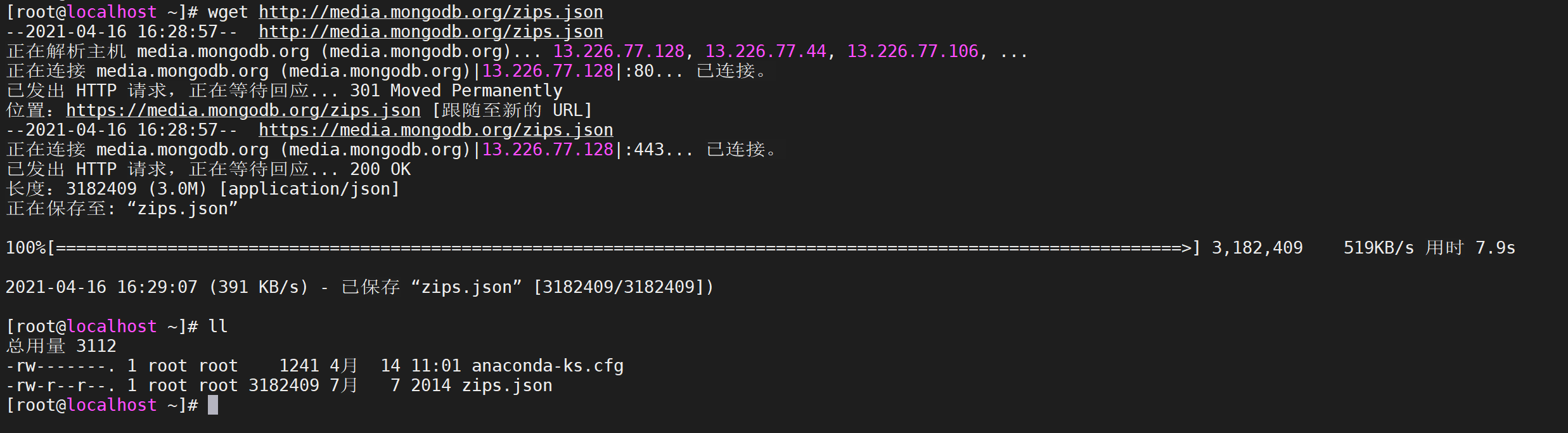
使用
wget命令下载包含示例数据的 JSON 文
1 | wget http://media.mongodb.org/zips.json |
导入数据文文档
使用
mongoimport命令将数据导入新数据库 (zips-db)
1 | mongoimport --host 127.0.0.1:27017 --db zips-db --file zips.json |

验证导入文档
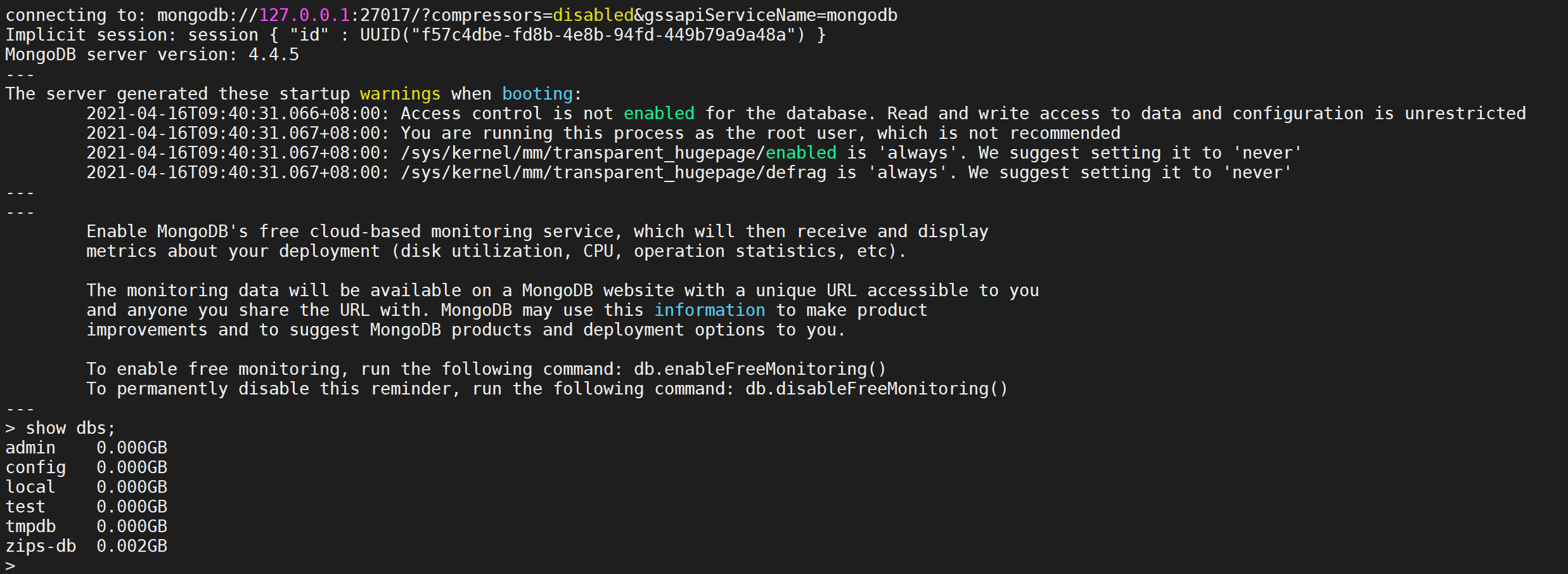
导入完成后,请使用
mongo连接到 MongoDB 并验证数据是否已成功加载
1 | mongo --host 127.0.0.1:27017 |
登录后检查发现所有的数据库都是存在的
并检查文档数据
1 | 切换到zips-db数据库 |
我们发现数据库已经成功导入

测试数据结构
导入的数据是亚马逊官方提供的没有各个地区的人数统计,数据结构如下
| _id | city | loc | pop(万) | state |
|---|---|---|---|---|
| 数据ID号 | 城市名称 | 位置坐标 | 人数 | 所属哪个州 |
具体对应关系如下图

关系表达式
刚才我们只学习了最基本的查询,下面我们看一下MongoDB的关系表达式
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
等于
标准写法
等于的操作符是
$eq,我们可以查询城市名称是CUSHMAN的数据
1 | db.zips.find({"city":{$eq:"CUSHMAN"}}).pretty(); |
这样我们发现查询出来两条数据

简写方式
查询城市是
CUSHMAN的数据,如果一个条件可以直接简写为如下形式
1 | db.zips.find({"city":"CUSHMAN"}).pretty(); |
我们找到两个城市名称是
CUSHMAN的数据

小于&小于等于
小于的操作符号是
$lt,我们查询城市人数小于 10万的城市有哪
1 | db.zips.find({"pop":{$lt:10}}).pretty(); |
我们发现美国有很多州的人口小于十万人

小于等于的操作符号是
$lte,我们查询城市没有人的城市,也就是小于等于0的城市
1 | db.zips.find({"pop":{$lte:0}}).pretty(); |

大于&大于等于
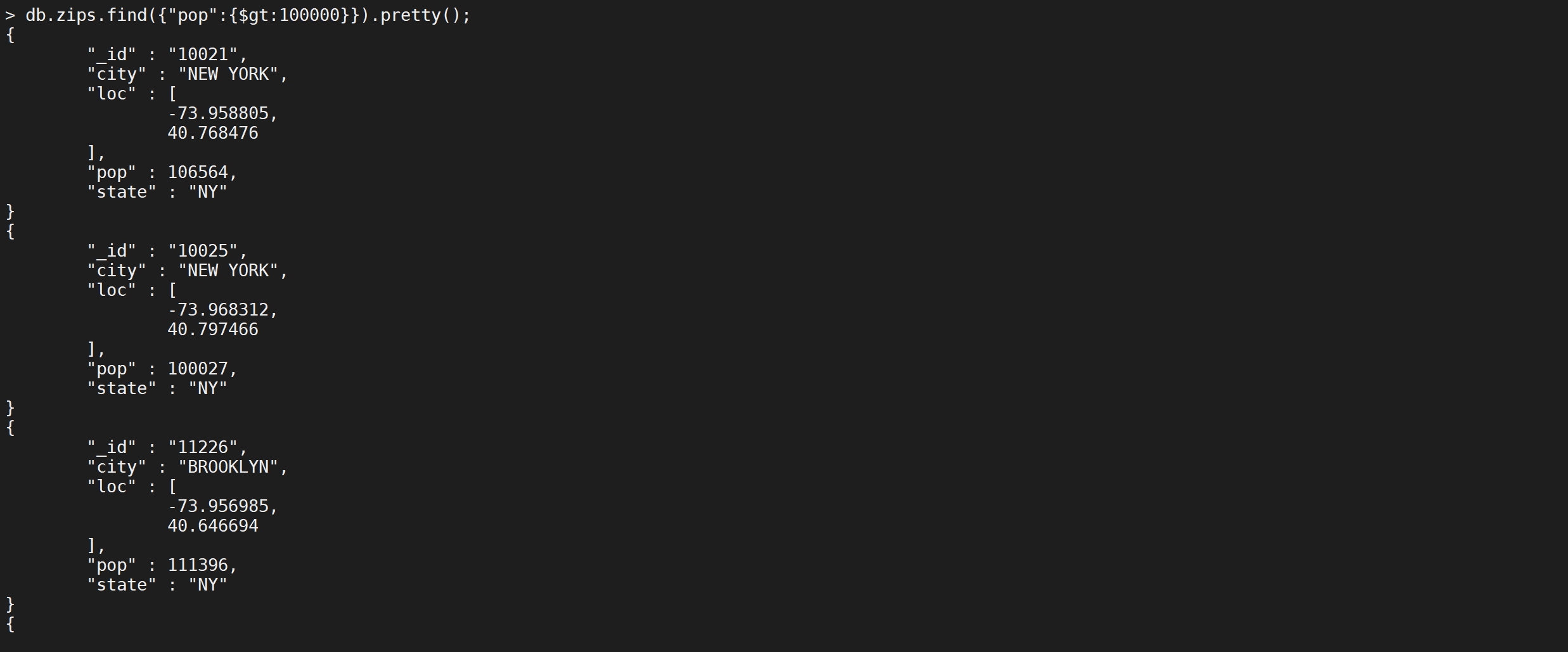
小于的操作符号是
$gt,我们查询城市人数大于 十亿的城市有哪因为城市的人数单位是万所以是大于十万万人
1 | db.zips.find({"pop":{$gt:100000}}).pretty(); |
第一个符合我们需求的城市就是纽约
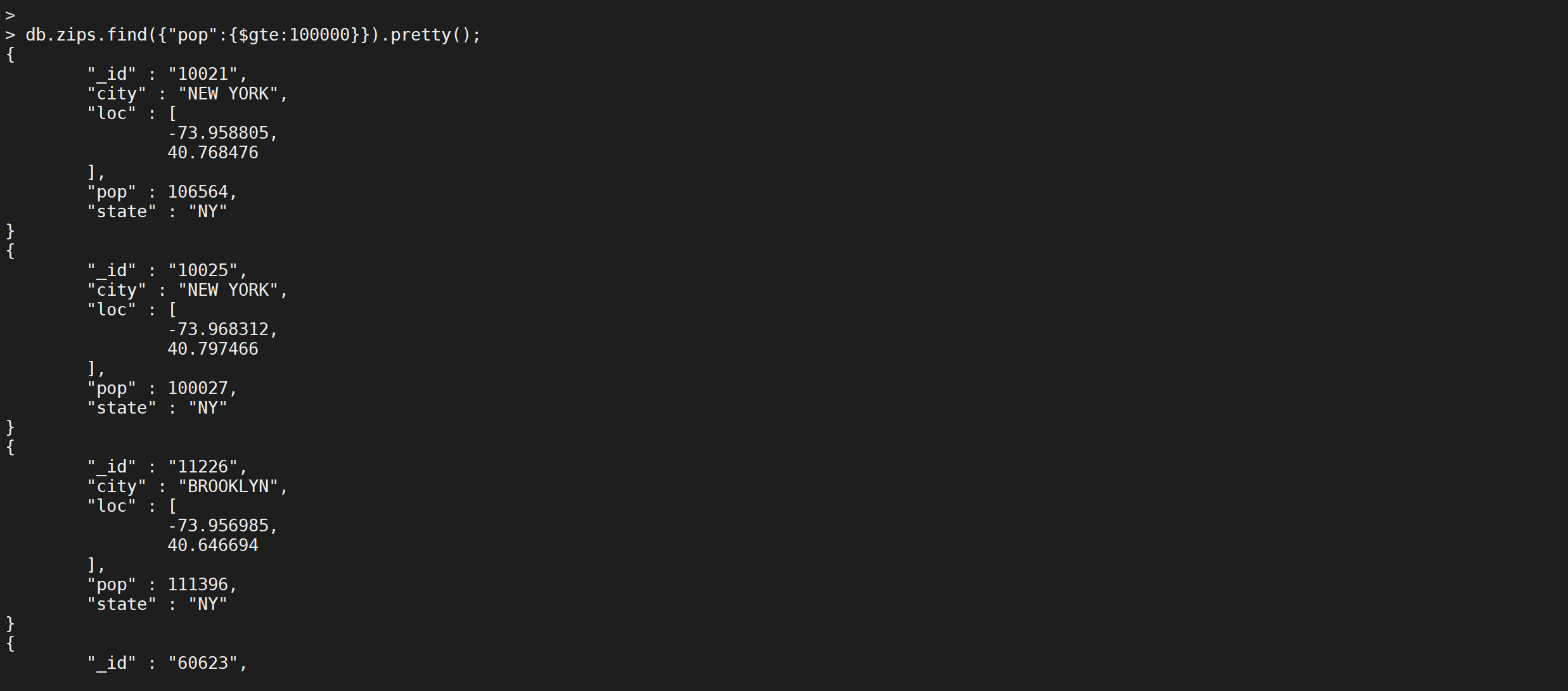
大于等于的操作符号是
$gte,我们来练习下
1 | db.zips.find({"pop":{$gte:900000}}).pretty(); |
不等于
不等于的操作符号是
$ne,我们可以搜索城市人数不是0的城市
1 | db.zips.find({"pop":{$ne:0}}).pretty(); |
这样我们就找到了城市不是0的数据,是不是很简单呢

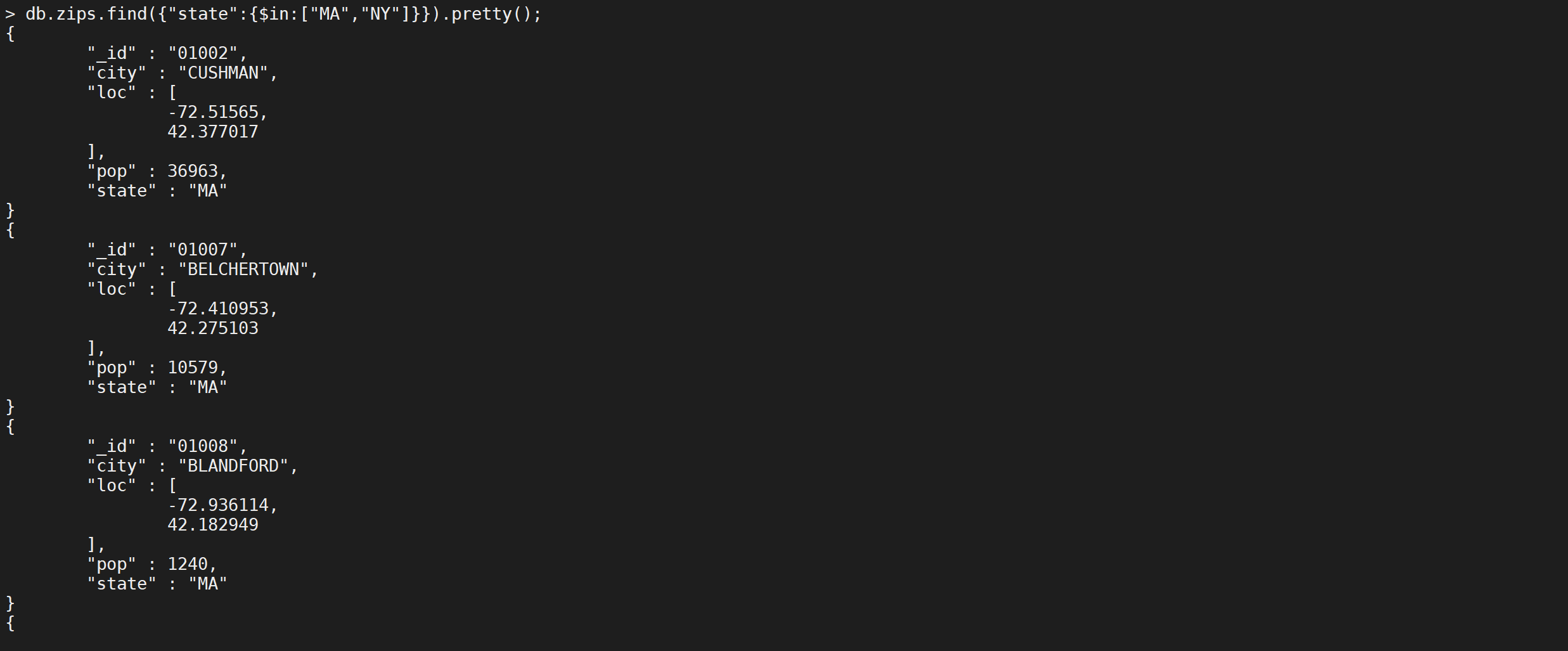
包含查询
IN查询的符号是
$in,使用方式如下
1 | db.zips.find({"state":{$in:["MA","NY"]}}).pretty(); |
我们只查询城市名称缩写是
MA以及NY的文档
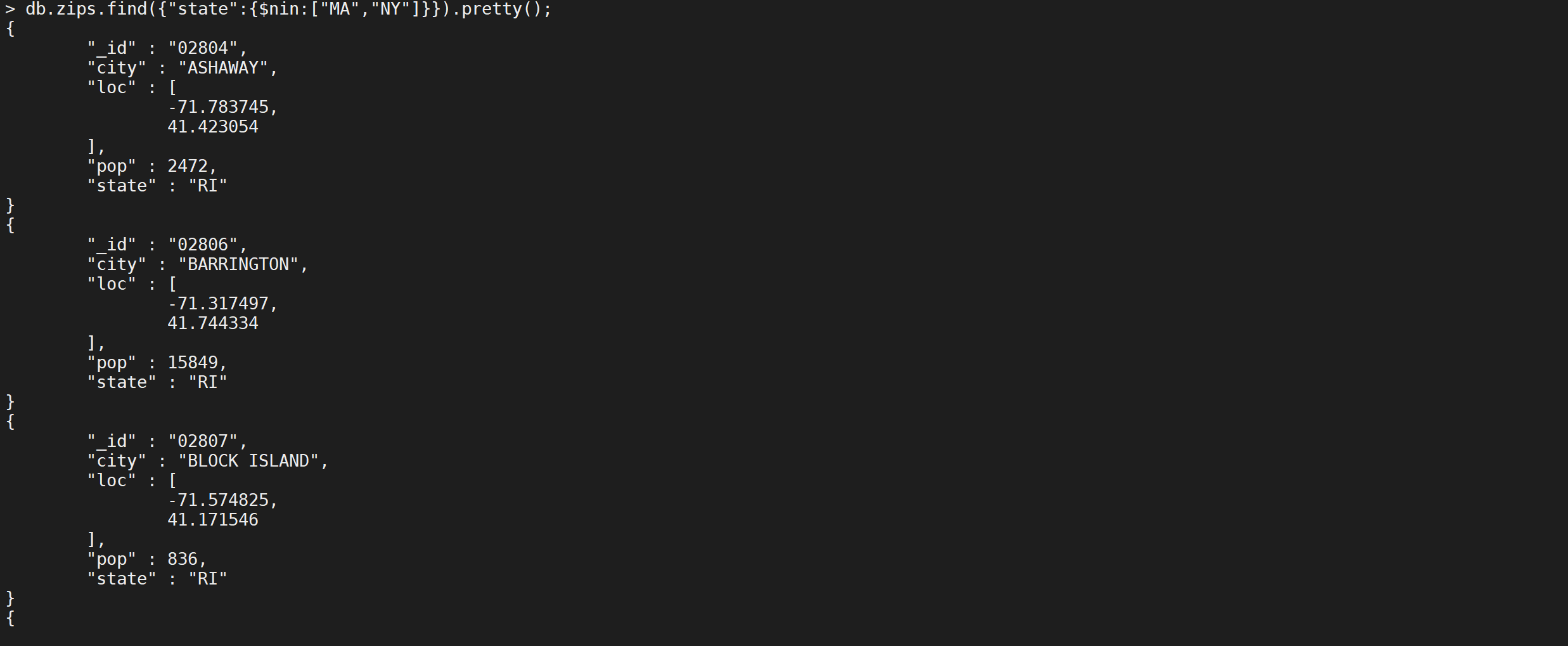
不包含查询
NIN相当于MySQL的
NOT IN查询,操作符号是$nin,我们查询城市名称缩写不是MA以及NY的文档
1 | db.zips.find({"state":{$nin:["MA","NY"]}}).pretty(); |
这样我们就把数据给查询出来了
判断字段存在
mongodb是一个文档型数据库,对于表结构没有严格定义,有时候可能缺少字段,如果要查询缺失的字段可以使用
$exists判断字段释放存在
1 | db.zips.find({"state":{$exists:false}}).pretty(); |
我们发现没有缺失
state字段的数据

多条件查询
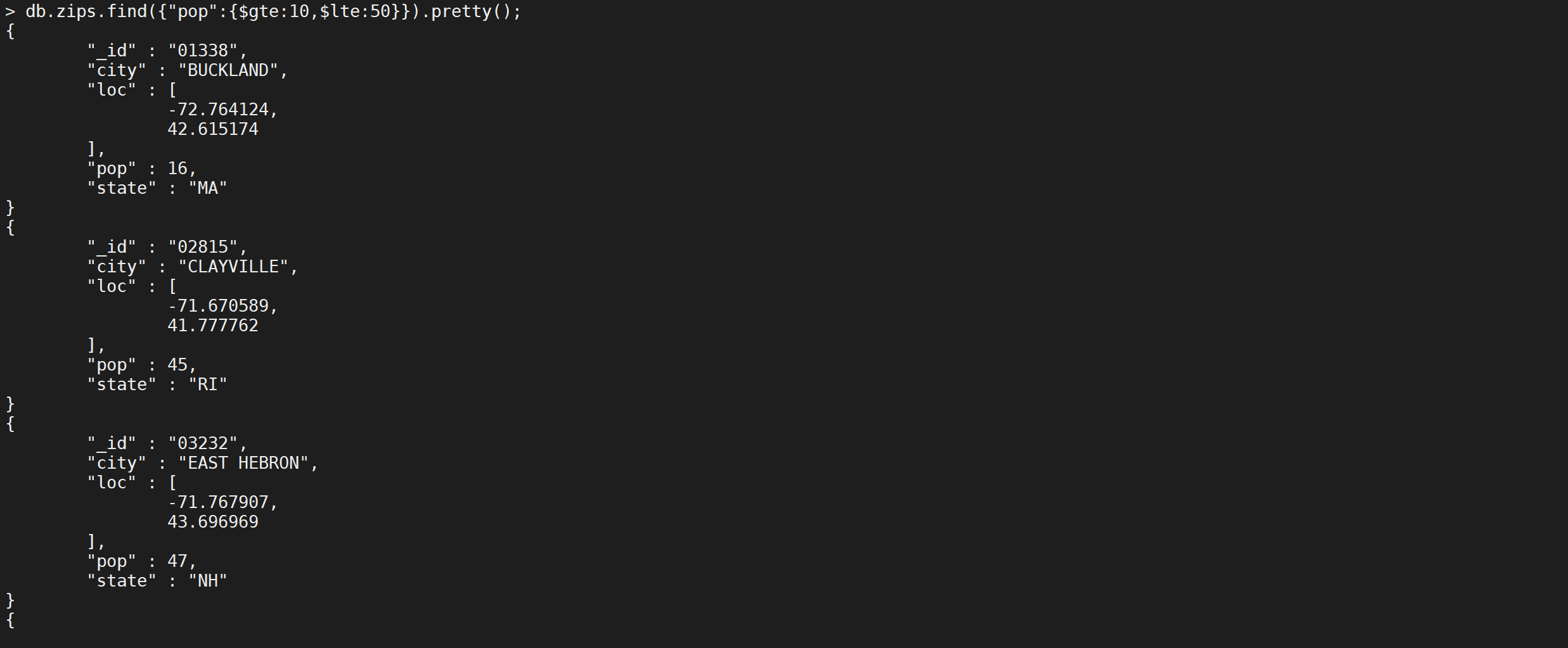
有时候存在一个字段需要多个条件,比如
pop>=10 and pop<50这个如果表示呢
1 | db.zips.find({"pop":{$gte:10,$lte:50}}).pretty(); |
这样就查询出来了人数在10-50万之间的城市
逻辑表达式
mongodb的逻辑表达式有以下几种
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| AND | {<key>:<value>,<key>:<value>} |
db.col.find("by":"菜鸟教程", "title":"MongoDB 教程").pretty() |
where by = '菜鸟教程 and title='MongoDB 教程' |
| OR | $or: [{key1: value1}, {key2:value2}] |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| NOT | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
AND 条件
标准写法
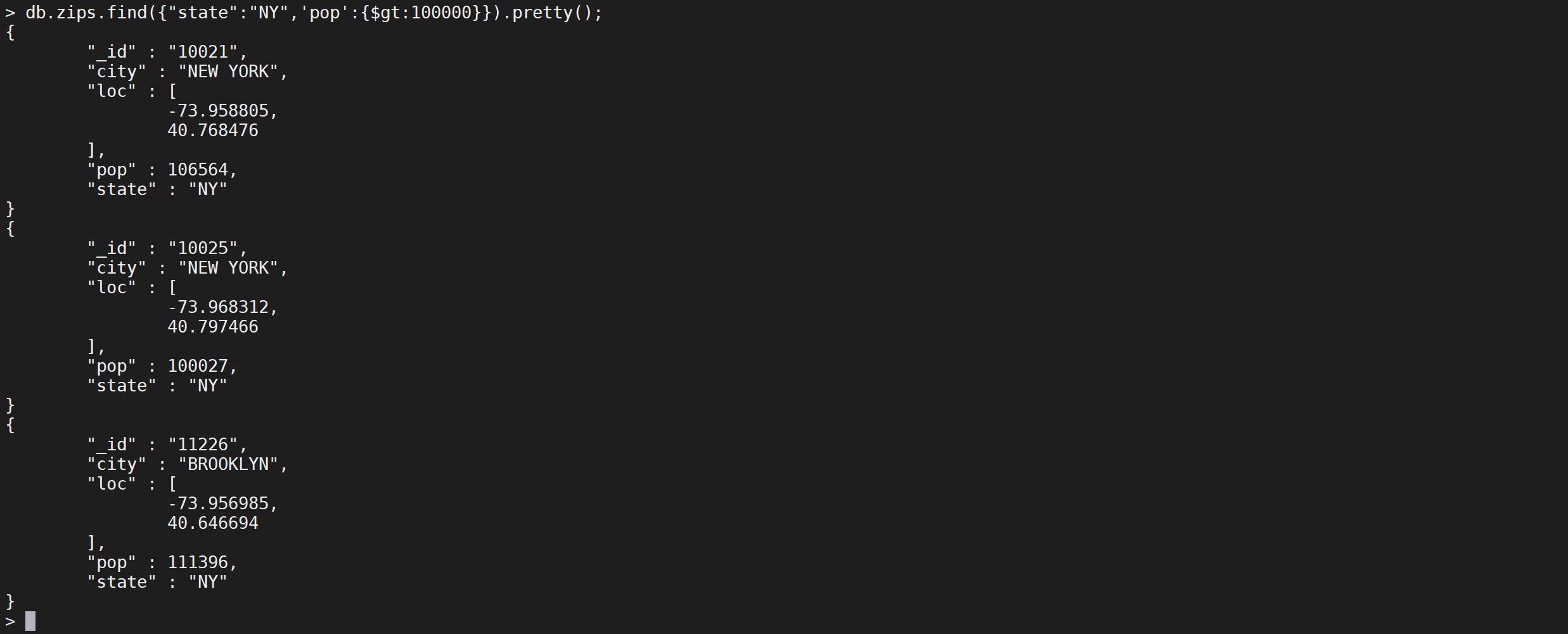
AND的标准写法的操作符是
$and,下面是查询,我们查询 城市缩写是NY并且人数大于一亿的文档
1 | db.zips.find({$and:[{"state":"NY"},{'pop':{$gt:100000}}]}).pretty(); |
这样就查询出来了

简写形式
如果只有一个AND操作MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
1 | db.zips.find({"state":"NY",'pop':{$gt:100000}}).pretty(); |
OR 条件
MongoDB OR 条件语句使用了关键字 $or,我们查询人数小于0 并且城市缩写是
NY的城市。
1 | db.zips.find({$or:[{"state":"NY"},{'pop':{$lt:0}}]}).pretty(); |
这样我们就把所以符合条件的数据筛选出来了

NOT 条件
$not是NOT的操作符,和其他的用法不太一样,使用方法如下
1 | db.zips.find({"pop":{$not:{$gte:10}}}).pretty(); |
这样是查询人数 小于十万人的城市

多个条件表达式
我们用一个多条件查询语句,具体语句如下
1 | db.zips.find({$or:[{$and:[{"state":"NY"},{'pop':{$gt:10,$lte:50}}]},{$and:[{"state":{$in:["MD","VA"]}},{'pop':{$gt:10,$lte:50}}]}]}).pretty(); |
这个语句的sql形式如下
1 | select * from zips where (state='NY' and pop>10 and pop <= 50) or (state in('MD','VA') and and pop>10 and pop <= 50) |
查询结果如下

排序
在MongoDB中使用使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
语法格式
sort()方法基本语法如下所示
1 | db.COLLECTION_NAME.find().sort({KEY1:1,KEY2:0,....}) |
升序查询
按照城市人数的升序查询
1 | db.zips.find().sort({"pop":1}).pretty(); |
我们发现数据是从小到达的升序

降序查询
按照城市人数的降序查询
1 | db.zips.find().sort({"pop":-1}).pretty(); |
我们发现数据是从大到小的降序

组合查询
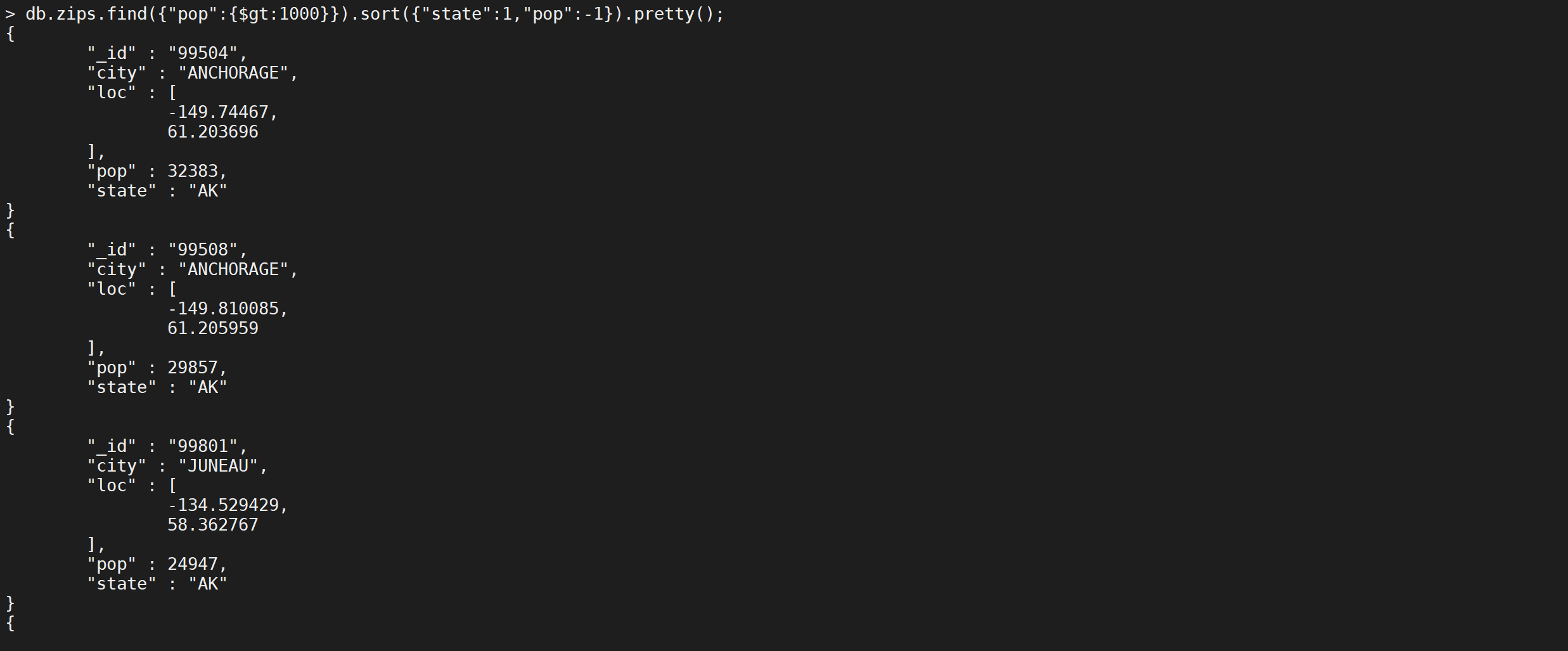
我们查询人数大于1000万,并且先按照城市缩写升序排,如果城市缩写相同再按照人数降序排
1 | db.zips.find({"pop":{$gt:1000}}).sort({"state":1,"pop":-1}).pretty(); |
分页查询
传统关系数据库中都提供了基于row number的分页功能,切换MongoDB后,想要实现分页,则需要修改一下思路。
传统分页思路
1 | #page 1 |
对应的sql是
1 | select * from tables limit(pagesize*(pageIndex-1)+1,pagesize) |
MongoDB的分页
MongoDB提供了skip()和limit()方法。
- skip: 跳过指定数量的数据. 可以用来跳过当前页之前的数据,即跳过pageSize*(n-1)。
- limit: 指定从MongoDB中读取的记录条数,可以当做页面大小pageSize。
前30条的数据是
1 | db.zips.find({},{"_id":1}).limit(30); |

所以可以这样实现分析
1 | 第一页数据 |

遇到的问题
看起来,分页已经实现了,但是官方文档并不推荐,说会扫描全部文档,然后再返回结果。
1 | The cursor.skip() method requires the server to scan from the beginning of the input results set before beginning to return results. As the offset increases, cursor.skip() will become slower. |
所以,需要一种更快的方式,其实和mysql数量大之后不推荐用limit m,n一样,解决方案是先查出当前页的第一条,然后顺序数pageSize条,MongoDB官方也是这样推荐的。
正确的分页办法
我们假设基于_id的条件进行查询比较,事实上,这个比较的基准字段可以是任何你想要的有序的字段,比如时间戳
实现步骤如下
- 对数据针对于基准字段排序
- 查找第一页的最后一条数据的基准字段的数据
- 查找超过基准字段数据然后向前找pagesize条数据
1 | 第一页数据 |

这样就可以一页一页的向下搜索,但是对于跳页的情况不太友好了。
ObjectId有序性
ObjectId生成规则
比如
"_id" : ObjectId("5b1886f8965c44c78540a4fc")
取id的前4个字节。由于id是16进制的string,4个字节就是32位,对应id前8个字符。即5b1886f8, 转换成10进制为1528334072. 加上1970,就是当前时间。
事实上,更简单的办法是查看org.mongodb:bson:3.4.3里的ObjectId对象。
1 | public ObjectId(Date date) { |
ObjectId存在的问题
MongoDB的ObjectId应该是随着时间而增加的,即后插入的id会比之前的大。但考量id的生成规则,最小时间排序区分是秒,同一秒内的排序无法保证。当然,如果是同一台机器的同一个进程生成的对象,是有序的。
如果是分布式机器,不同机器时钟同步和偏移的问题。所以,如果你有个字段可以保证是有序的,那么用这个字段来排序是最好的。_id则是最后的备选方案,可以考虑增加 雪花算法ID作为排序ID
跳页问题
上面的分页看起来看理想,虽然确实是,但有个刚需不曾指明—我怎么跳页。
我们的分页数据要和排序键关联,所以必须有一个排序基准来截断记录。而跳页,我只知道第几页,条件不足,无法分页了。
现实业务需求确实提出了跳页的需求,虽然几乎不会有人用,人们更关心的是开头和结尾,而结尾可以通过逆排序的方案转成开头。所以,真正分页的需求应当是不存在的。如果你是为了查找某个记录,那么查询条件搜索是最快的方案。如果你不知道查询条件,通过肉眼去一一查看,那么下一页足矣。
在互联网发展的今天,大部分数据的体量都是庞大的,跳页的需求将消耗更多的内存和cpu,对应的就是查询慢,当然,如果数量不大,如果不介意慢一点,那么skip也不是啥问题,关键要看业务场景。
统计查询
MongoDB除了基本的查询功能之外,还提供了强大的聚合功能,这里将介绍一下
count,distinct
count
查询记录的总数,下面条件是查询人数 小于十万人的城市的数量
1 | db.zips.find({"pop":{$not:{$gte:10}}}).count(); |

这样就查询出来符合条件的数据的条数是 118个,还可以写成另外一个形式
1 | db.zips.count({"pop":{$not:{$gte:10}}}); |

distinct
无条件排重
用来找出给定键的所有不同的值
1 | db.zips.distinct("state"); |
这样就按照state字段进行去重后的数据

有条件排重
对于城市人数是七千万以上的城市的缩写去重
1 | db.zips.distinct("state",{"pop":{$gt:70000}}); |
