堆外内存

堆内内存
“Java 虚拟机具有一个堆(Heap),堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在 Java 虚拟机启动时创建的。”
也就是说,平常我们老遇见的那位,JVM启动时分配的,就叫作堆内存(即堆内内存)。
对象的堆内存由称为垃圾回收器的自动内存管理系统回收。
此外,堆的内存不需要是连续空间,因此堆的大小没有具体要求,既可以固定,也可以扩大和缩小。
我们在jvm参数中只要使用-Xms,-Xmx等参数就可以设置堆的大小和最大值,理解jvm的堆还需要知道下面这个公式:堆内内存 = 新生代+老年代+持久代
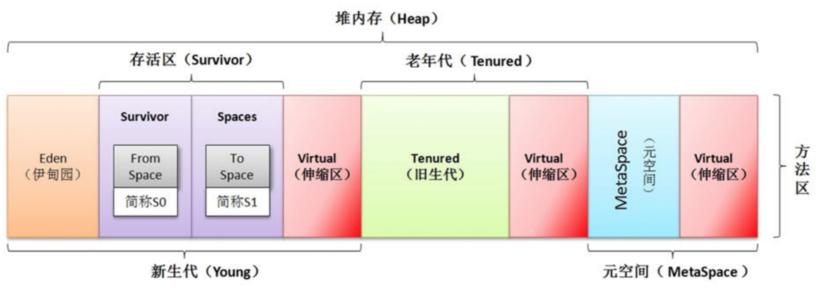
在使用堆内内存(on-heap memory)的时候,完全遵守JVM虚拟机的内存管理机制,采用垃圾回收器(GC)统一进行内存管理,GC会在某些特定的时间点进行一次彻底回收,也就是Full GC,GC会对所有分配的堆内内存进行扫描。
注意:在这个过程中会对JAVA应用程序的性能造成一定影响,还可能会产生Stop The World。
堆外内存
显然,看名字就知道堆外内存与堆内内存是相对应的:Java 虚拟机管理堆之外的内存,称为非堆内存,即堆外内存。
换句话说:堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
那堆外内存都有什么
Java 虚拟机具有一个由所有线程共享的方法区。方法区属于非堆内存。它存储每个类结构,如运行时常数池、字段和方法数据,以及方法和构造方法的代码。它是在 Java 虚拟机启动时创建的。
方法区在逻辑上属于堆,但 Java 虚拟机实现可以选择不对其进行回收或压缩。与堆类似,方法区的内存不需要是连续空间,因此方法区的大小可以固定,也可以扩大和缩小。。
除了方法区外,Java 虚拟机实现可能需要用于内部处理或优化的内存,这种内存也是非堆内存。例如,JIT 编译器需要内存来存储从 Java 虚拟机代码转换而来的本机代码,从而获得高性能。
堆外内存的申请和释放
JDK的ByteBuffer类提供了一个接口allocateDirect(int capacity)进行堆外内存的申请。
底层通过unsafe.allocateMemory(size)实现,Netty、Mina等框架提供的接口也是基于ByteBuffer封装的。
现在我们先看看在JVM层面是如何实现堆外内存申请的。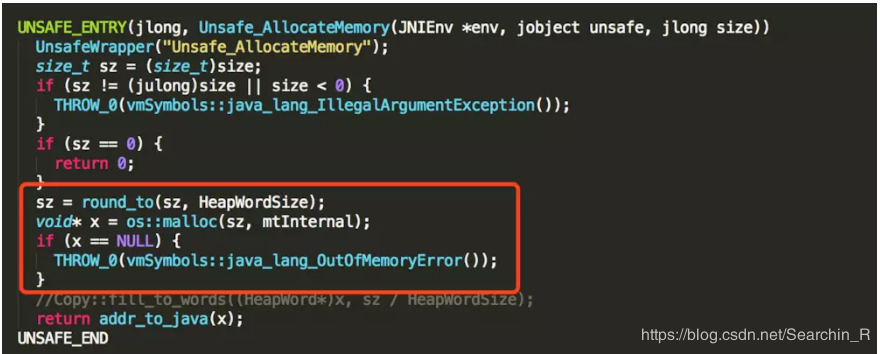
可以发现,unsafe.allocateMemory(size)的最底层是通过malloc方法申请的,但是这块内存需要进行手动释放,JVM并不会进行回收,幸好Unsafe提供了另一个接口freeMemory可以对申请的堆外内存进行释放。

看完堆外内存申请的底层实现,想必大家对它的实现就有了一些基础了解。
接下来我们再看看DirectByteBuffer()的构造方法。
其构造方法如下
1 | DirectByteBuffer(int cap) { |
从上面的代码我们可以知道,在Cleaner 内部中通过一个列表,维护了针对每一个 directBuffer 的一个回收堆外内存的线程对象(Runnable),而回收操作就是发生在 Cleaner 的 clean() 方法中。
Cleaner源码如下
1 | private Cleaner(Object var1, Runnable var2) { |
Deallocator的源码如下
1 | private static class Deallocator implements Runnable { |
配置
可以通过 -XX:MaxDirectMemorySize 参数来设置最大可用直接内存,如果启动时未设置则默认为最大堆内存大小,即与 -Xmx 相同。即假如最大堆内存为1G,则默认直接内存也为1G,那么 JVM 最大需要的内存大小为2G多一些。当直接内存达到最大限制时就会触发GC,如果回收失败则会引起OutOfMemoryError。
分配内存耗时
环境为JDK9,两种内存分配的耗时如下,运行两遍让其预热。可以看到直接内存的分配比较耗时,而堆内存分配操作耗时少好几倍。
1 | public static void directMemoryAllocate() { |
输出
1 | direct memory allocate: 104 ms |
读写操作耗时
环境为JDK9,两种内存的读写操作耗时如下,同样运行两遍让其预热,可以看到直接内存读写操作的速度相对快一些。
1 | public static void memoryRW() { |
输出
1 | direct memory rw: 37 ms |
理论上直接内存的机制访问速度要快一些,但也不能武断地直接说直接内存快,另外,在内存分配操作上直接内存要慢一些。直接内存更适合在内存申请次数较少,但读写操作较频繁的场景。
堆外内存的使用场景
适合长期存在或能复用的场景
堆外内存分配回收也是有开销的,所以适合长期存在的对象
适合注重稳定的场景
堆外内存能有效避免因GC导致的暂停问题。
适合简单对象的存储
因为堆外内存只能存储字节数组,所以对于复杂的DTO对象,每次存储/读取都需要序列化/反序列化,
适合注重IO效率的场景
用堆外内存读写文件性能更好
堆外内存的回收机制
上文说到,“unsafe.allocateMemory(size)的最底层是通过malloc方法申请的,但是这块内存需要进行手动释放,JVM并不会进行回收,幸好Unsafe提供了另一个接口freeMemory可以对申请的堆外内存进行释放。”。那岂不是每一次申请堆外内存的时候,都需要在代码中显式释放吗?
很明显,并不是这样的,这种情况的出现对于Java这门语言来说显然不够合理。那既然JVM不会管理这些堆外内存,它们又是怎么回收的呢?
这里就要祭出大杀器了:DirectByteBuffer。
JDK中使用DirectByteBuffer对象来表示堆外内存,每个DirectByteBuffer对象在初始化时,都会创建一个对应的Cleaner对象,这个Cleaner对象会在合适的时候执行unsafe.freeMemory(address),从而回收这块堆外内存。
当初始化一块堆外内存时,对象的引用关系如下:
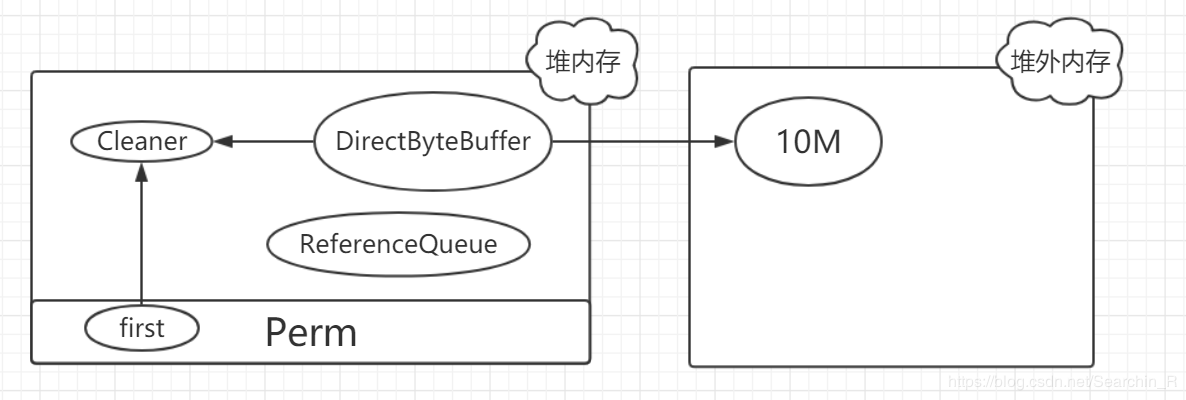
其中**first是Cleaner类的静态变量,Cleaner对象在初始化时会被添加到Clener链表中,和first形成引用关系,ReferenceQueue是用来保存需要回收的Cleaner**对象。
如果该DirectByteBuffer对象在一次GC中被回收了,即
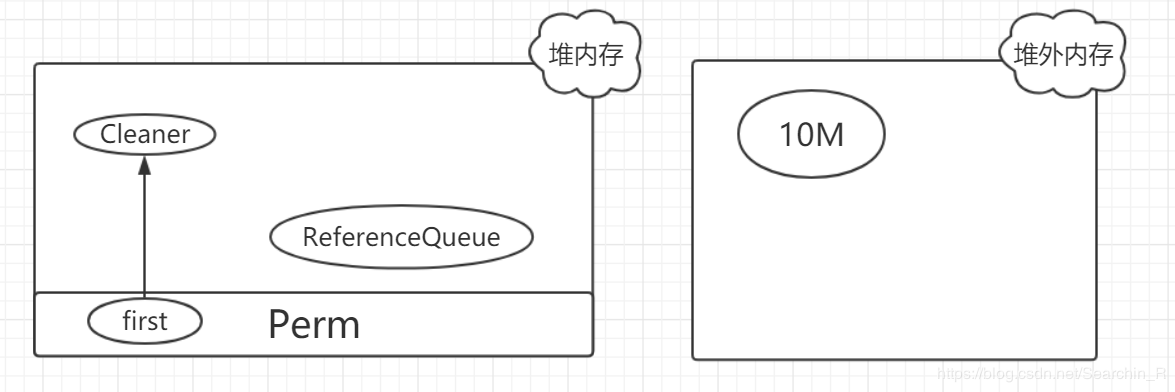
此时,只有**Cleaner对象唯一保存了堆外内存的数据(开始地址、大小和容量),在下一次FGC时,把该Cleaner对象放入到ReferenceQueue中,并触发clean**方法。
Cleaner对象的clean方法主要有两个作用:
- 把自身从
Cleaner链表删除,从而在下次GC时能够被回收 - 释放堆外内存
源码如下:
1 | public void run() { |
看到这里,可能有人会想,如果JVM一直没有执行FGC的话,无效的Cleaner对象就无法放入到ReferenceQueue中,从而堆外内存也一直得不到释放,无效内存就会很大,那怎么办?
这个倒不用担心,那些大神们当然早就考虑到这一种情况了。
其实,在初始化DirectByteBuffer对象时,会自动去判断,如果堆外内存的环境很友好,那么就申请堆外内存;如果当前堆外内存的条件很苛刻时(即有很多无效内存没有得到释放),这时候就会主动调用System.gc()强制执行FGC,从而释放那些无效内存。
为了避免这种悲剧的发生,也可以通过-XX:MaxDirectMemorySize来指定最大的堆外内存大小,当使用达到了阈值的时候将调用System.gc来做一次full gc,以此来回收掉没有被使用的堆外内存。
源码如下:
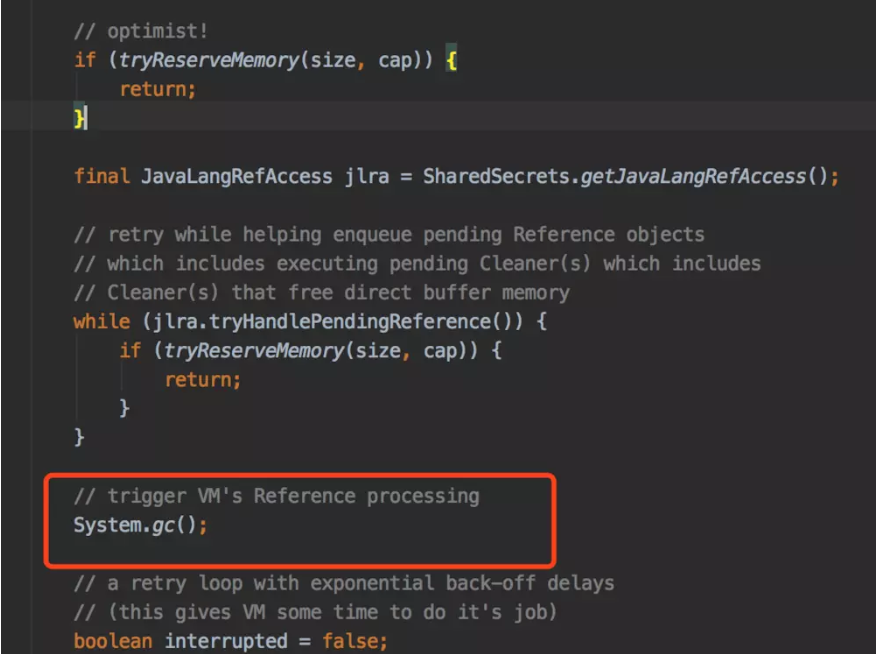
当然,源程序毕竟不是万能的,做项目的时候经常有千奇百怪的情况出现。
比如很多线上环境的JVM参数有-XX:+DisableExplicitGC,导致了System.gc()等于一个空函数,根本不会触发FGC,因此在使用堆外内存时,要格外小心,防止内存一直得不到释放,造成线上故障。这一点在使用Netty框架时需要格外注意。
总而言之,不论是什么东西,都不是绝对安全的。对于各类代码,我们都得多加留心。
System.gc的作用有哪些
使用了System.gc的作用是什么?
做一次full gc
执行后会暂停整个进程。
System.gc我们可以禁掉,使用-XX:+DisableExplicitGC,
其实一般在cms gc下我们通过-XX:+ExplicitGCInvokesConcurrent也可以做稍微高效一点的gc,也就是并行gc。最常见的场景是RMI/NIO下的堆外内存分配等
注意
如果我们使用了堆外内存,并且用了DisableExplicitGC设置为true,那么就是禁止使用System.gc,这样堆外内存将无从触发极有可能造成内存溢出错误(这种情况在四中有提及),在这种情况下可以考虑使用ExplicitGCInvokesConcurrent参数。
说起Full gc我们最先想到的就是stop thd world,这里要先提到VMThread,在jvm里有这么一个线程不断轮询它的队列,这个队列里主要是存一些VM_operation的动作,比如最常见的就是内存分配失败要求做GC操作的请求等,在对gc这些操作执行的时候会先将其他业务线程都进入到安全点,也就是这些线程从此不再执行任何字节码指令,只有当出了安全点的时候才让他们继续执行原来的指令,因此这其实就是我们说的stop the world(STW),整个进程相当于静止了。
使用堆外内存的优缺点
优点
当然,任何一个事物使用起来有优点就会有缺点,堆外内存的缺点就是内存难以控制,使用了堆外内存就间接失去了JVM管理内存的可行性,改由自己来管理,当发生内存溢出时排查起来非常困难。 所以,还是那句话,使用的时候要多留心呀~
- 可以扩展至更大的内存空间。比如超过1TB甚至比主存还大的空间;
- 减少了垃圾回收(因为垃圾回收会暂停其他的工作。);
- 可以在进程间共享,减少JVM间的对象复制,使得JVM的分割部署更容易实现(堆内在flush到远程时,会先复制到直接内存(非堆内存),然后在发送;而堆外内存相当于省略掉了这个工作。);
- 它的持久化存储可以支持快速重启,同时还能够在测试环境中重现生产数据
- 加快了复制的速度。因为堆内在flush到远程时,会先复制到直接内存(非堆内存),然后在发送;而堆外内存相当于省略掉了这个工作。
- 站在系统设计的角度来看,使用堆外内存可以为你的设计提供更多可能。最重要的提升并不在于性能,而是决定性的
缺点
而福之祸所依,自然也有不好的一面:
- 堆外内存难以控制,如果内存泄漏,那么很难排查
- 堆外内存相对来说,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较适合。
使用堆外内存使用问题
堆外内存及测试
高性能计算领域最大的一个难点在于重现那些隐蔽的BUG,并证实问题已经得到修复。通过将输入事件及数据以持久化的形式存储到堆外内存中,你可以将你的关键系统变成一系列的复杂状态机。(简单的情况下只有一个状态机)。这样的话在测试环境便能够复现出生产环境出现的行为及性能问题了。
许多投行都通过这项技术来可靠地重现当天系统对某个事件的响应,并分析出该事件之所以这么处理的原因。更为重要的是,你能够立即证明线上的故障已经得到了解决,而不是发现一个问题后,寄希望于它就是引发线上故障的根源。确定性的行为还伴随着确定性的性能。
你可以在测试环境中按照真实的时间来回放事件,由此得到的时延分布也必定是生产环境中所出现的。由于硬件的不同,一些系统的抖动可能难以复现,不过这在数据分析的角度而言已经相当接近真实的情况了。为了避免出现花一整天的时间来回话前一天的数据的情况,你还可以增加一个阈值,比方说,如果两个事件的间隔超过10ms的话你可以就只等待10ms。这样你能够在一个小时内根据实际的时间来回放出一天的事件,来检查下你的改动是否对时延分布有所改善。
这样做是否就损失了“一次编译,处处执行”的好处了?
一定程度上来讲是这样的,但其实的影响比你想像的要小得多。越接近处理器,你就更依赖于处理器或者操作系统的行为。所幸的是,绝大多数系统使用的都是AMD/Intel的CPU,甚至是ARM处理器在底层上也越来越与这两家兼容了。操作系统之间也存在差别,因此相对于Windows而言,这项技术更适合在Linux系统上使用。如果你是在Mac OS X或者Windows上开发,然后生产环境是部署在Linux上的话,就一点问题都没有了。我们在Higher Frequency Trading中也是这么做的。
使用堆外内存会引入什么新的问题
天下没有免费的午餐,堆外内存也不例外。最大的问题在于你的数据结构变得有些别扭。要么就是需要一个简单的数据结构以便于直接映射到堆外内存,要么就使用复杂的数据结构并序列化及反序列化到内存中。很明显使用序列化的话会比较头疼且存在性能瓶颈。使用序列化比使用堆对象的性能还差。
在金融领域,许多高频率的数据都是扁平的简单结构,全部由基础类型组成,非常适合映射到堆外内存。然而,并非所有的应用程序都是这样的,可能会有一些嵌套得很深的数据结构,比如说图,你还不得不将这些对象缓存在堆上。
另外一个问题就是JVM会制约到你对操作系统的使用。你不用再担心JVM会给系统造成过重的负载。使用堆外内存后,某些限制已经不复存在了,你可以使用比主存还大的数据结构,不过如果你这么做的话又得考虑一下使用的是什么磁盘子系统了。比如说,你肯定不会希望分页到一块只有80 IOPS(Input/Ouput Operations per Second,每秒的IO操作)的HDD硬盘上,最好是IOPS能到80,000的SSD硬盘,当然了,1000x的话更好。